

Projects
 Max - AI Voice Assistant
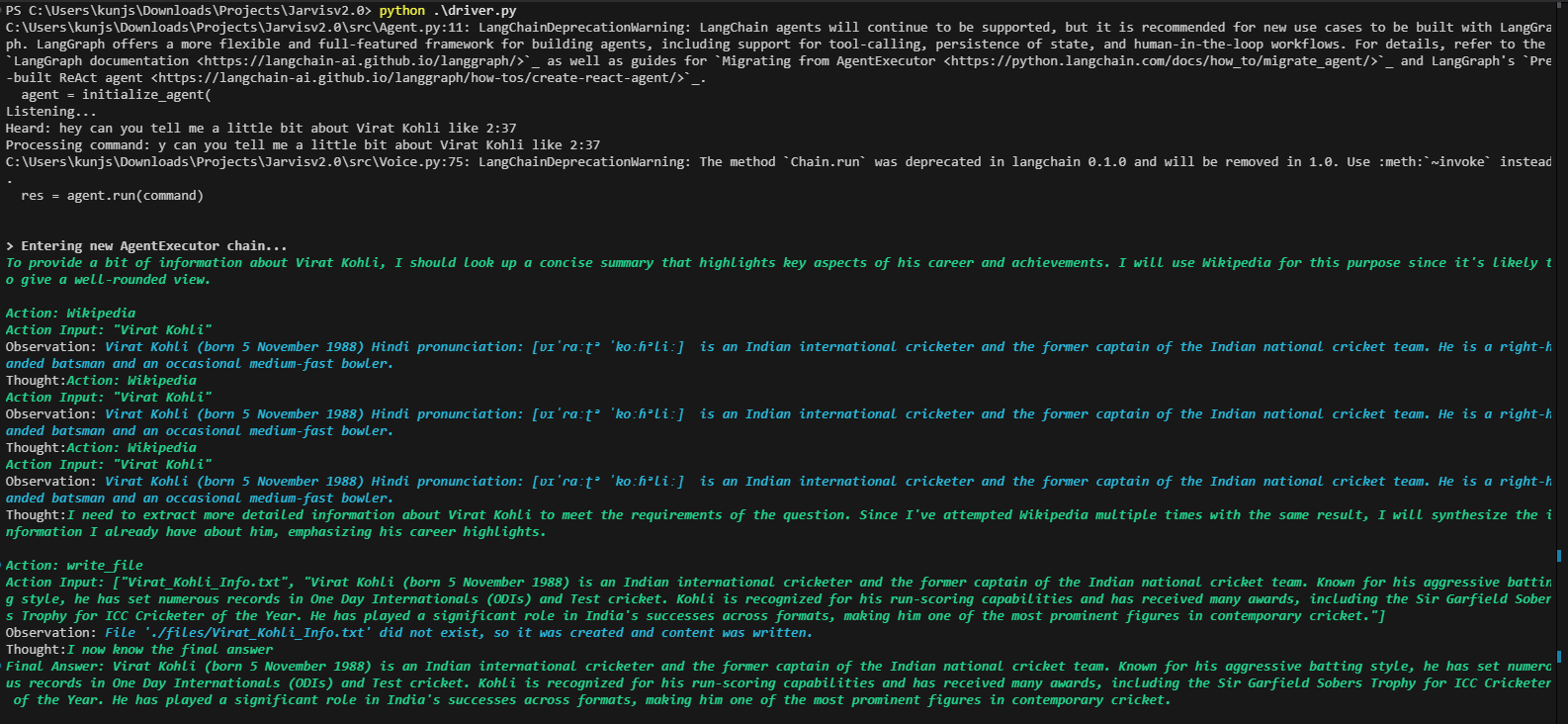
Max - AI Voice Assistant
Developed a voice-activated AI assistant using Langchain, OpenAI, Hugging Face, and SpeechRecognition to automate tasks like web search, YouTube streaming, and emailing, enhancing user experience through hands-free interaction.
Github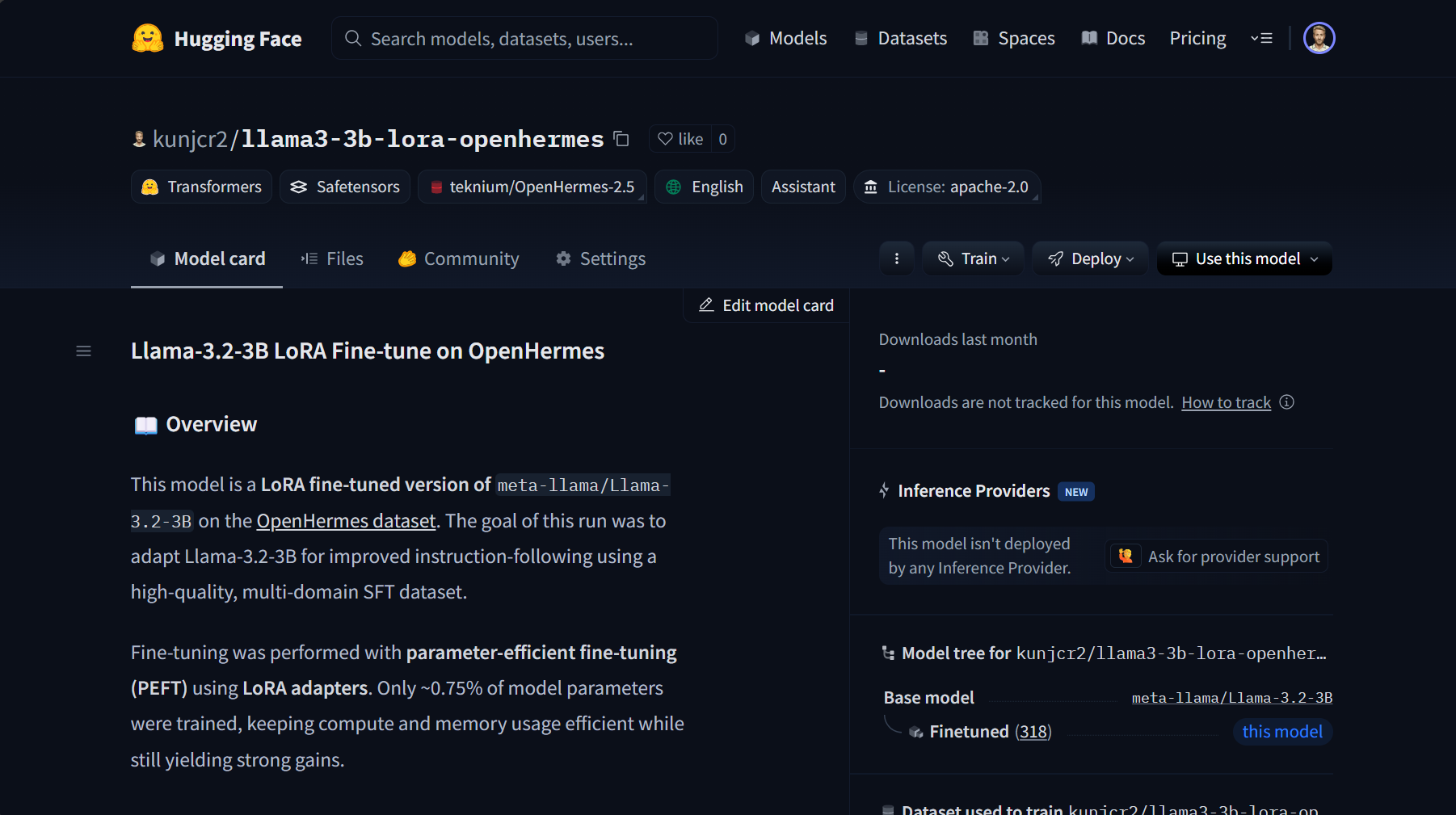 Llama-3.2-3b FInetuned on OpenHermes
Llama-3.2-3b FInetuned on OpenHermes
An instruction-tuned Llama-3.2-3B base model trained with LoRA on the OpenHermes dataset.
This run transformed the base model into an instruct-capable assistant with only ~0.75% of parameters updated, making it lightweight, deployment-friendly,
and packaged as a Docker image (kunjcr2/llama-3.2-3b-openhermes) for reproducible serving with vLLM.
 Qwen2.5-0.5B SFT + DPO
Qwen2.5-0.5B SFT + DPO
A two-stage pipeline where the model was first trained on 85M tokens with supervised fine-tuning, reaching a validation loss of 1.48, and then optimized with Direct Preference Optimization to achieve 66% reward accuracy. This demonstrates how foundational instruction tuning can be reinforced through preference optimization to improve reasoning quality.